Herve Jegou, et al., Aggregating local descriptors into a compact image representation, Proc. IEEE CVPR'10 The goal of the work is reducing the computing time and the memory usage without lossing too much accuracy in image retrieval for large scale data. This work consists of two parts: VLAD and vector encoding.
VLAD
Inspired by Fisher kernel, they introduce VLAD(vector of locally aggregated descriptors) to represent) to represent an image. The VLAD is processed as follows.
First, train a visual words codebook
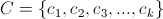
by K-means, where $latex c_i $ means the i'th centroid, and $latex c_i$ is a dimension d sift vector.
Second, for the sift vector of each image $latex x$, whose dimension = d, aggregate the difference between $latex x$ and its nearest centroid $latex c_i $ to generate $latex v_{i,j}$ as bellow, where i means the number of centroid and j means the number of the component of sift vector. $latex v's $ dimension $latex D = k * d$.
Finally, the vector v is subsequently L2-normalized by $latex v := v/||v||^2 $.
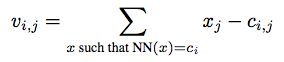
Approximating nearest neighbors
Indexation-aware dimensionality reduction
To make nearest neighbor search more efficiently by approximating, they proposed ADC approach, which quantize each sub-vector. They also find that VLAD is sparse and structured, which is appropriate for PCA to reduce dimensionality. To consider that PCA transformed vector's variance is not equal, it can employ Householder matrix to balance variance; besides, they find that random orthogonal matrix also performs well according to the experiment result.
My comment
The paper contribution is proposing VLAD to represent image and using ADC approach and PCA to compress data. The experiment shows that the VLAD they proposed performs better than "bag of features" method. This approach can make image retrieval more efficiently and more space economically.
Go Top