"Efficient visual search of videos cast as text retrieval," J. Sivic, and A. Zisserman, IEEE TPAMI, 2009 Paper Authors: Josef Sivic and Andrew Zisserman The following figures are all from this paper.

J. Sivic, and A. Zisserman proposed this method which analogizes searching in video to in text corpora: representing a visual region as a visual word such that it can employ text retrieval methods like inverted index, tf-idf...etc. The diagram not only performs well but also saves time efficiently. The system flowchart shows as above.
Visual words
The first thing to do is to convert image regions into visual words, which are symbols can represent key image regions like word terms' effect in articles. To do so, use two affine covariant regions detecting method: Shape Adapted (SA) and Maximally Stable (MS) to find significant regions, describe them with SIFT descriptors, cluster descriptor vectors with K-means using Mahalanbis distance as below, and transfer vectors into "visual words" according to the clustering result. Visual words not only can be represent image regions but also makes image retrieval more efficiently through inverted index method.
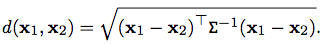
tf-idf weighted and Stop list
Borrowing the concept of tf-idf in text retrieval, the query vectors and retrieved frame vectors are weighted by the inverse document. And for the most frequent visual words in all most all image are suppressed, just like what Stop word list effects.
Spatial consistency
It is a accurate match not only hit one point but also the points surrounding the point are matched. Each region which also matches within the search areas, defined by the 15 nearest spatial neighbours of each match, casts a vote for that frame. Matches with no support are rejected. The final relevance score of the frame is determined by summing the spatial consistency votes, and adding the frequency score $latex sim( v_q , v_d ) $, the consine similarity between $latex v_q$ and $latex v_d$.
My comment
This work shows how cross-fields research can be possible and why it may be more useful: the well-developed techniques in other filed can be applied if we analogizes the problem to the other appropriately. However, there are still data specific attributes, just like spatial consistence, which should be processed more sophisticatedly. .
Go Top