總結
巨量機械學習需要處理的挑戰有二:(1) 訓練資料集過大 (2) 機械學習模型本身過於複雜,所需要訓練的參數過多。這兩個原因使得無法使用單一主機解決巨量機械學習的問題。為此,許多團隊於近幾年提出分布式機械學習系統,好著手處理巨量資料的挑戰。本篇整理了目前分布式巨量機械學習系統的三種典範:MapReduce, Data Graph, 和 Parameter Server.
為什麼我們需要分布式系統處理巨量機械學習?
"巨量"有兩種意義:(1) 訓練資料集過大 (2) 模型本身過度複雜,所需訓練的參數過多。因為這兩個原因,通常無法使用單一機器處理巨量機械學習的問題。為此,開發者得需要設計分布式系統,或者建立在已有的分布式計算框架來處理。
根據目前主流巨量機械學習系統的架構設計,可歸納為三種模式: MapReduce, Data Graph, 和 Parameter Server。
MapReduce 模式
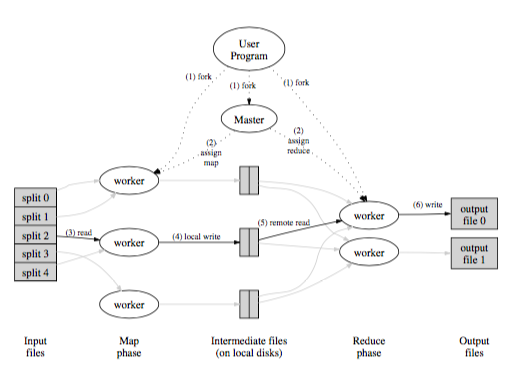
圖片 1. MapReduce (資料來源: [9])
MapReduce [9] 是很熱門的分布式計算框架, 而 Apache Hadoop [10] 則是對應的開源系統. 一般來說,MapReduce 有兩個階段:Map 和 Reduce。在 Map 階段,系統根據使用者提供的 Map 函式將輸入資料轉換成 key-value 的輸出資料。之後,MapReduce 系統會將同樣 key 的資料集合放到同一台機器做 Reduce 階段。 Reducer 會收到 key,和對應一連串的 value,根據使用者的函式做對應的操作,在儲存回分布式的資料系統裡面。
由於 MapReduce 是一套相當成熟的框架,許多研究致力於將原本的機械學習演算法拆解成多個循環組成的 Map 和 Reduce,將演算法實作在 MapReduce 框架上。其中 Mahout [1] 是一個很知名的開源專案,就是將機械學習演算法建立在 Hadoop之上 (注: Mahout社群在2014年4月決定將算法轉向開發在 Spark 上)。
Hadoop預設的設計上會把 Mapper 中間產生的 key-value 組,以及 Reducer 產生的key-value 組存回硬碟。但是,許多機械學習演算法需要多次的循環計算,直到符合終止條件 (例如: gradient decent)。多次的循環計算產生巨量的硬碟存儲,拖慢了整體計算的效率。
為了解決這個問題, Spark [2] 提供 Resilient Distributed Datasets (RDD),使用者可以指定將中介的計算結果存在記憶體當中(如果計算結果太大,則會存進硬碟),節省硬碟存儲的時間。根據他們的實驗,用 Spark 實作的 logistic regrsssion 和 k-means 演算法,可以比用 Hadoop 實作的版本快上20倍。 其中,MLlib 就是建立在 Spark 上熱門的巨量機械學習開源專案。
另外, Low 等人 (2012) [3] 指出建立在 MapReduce 上的機械學習演算法,通常會在 Map 階段產生重複內容的訊息傳遞給 Reduce,增加網路傳輸的成本。以 Pagerank為例,高 degree 的節點需要將自己的 Pagerank 值複製多份,以傳給所有的鄰居節點,而增加 Shuffle 階段的成本。
Data Graph 模式
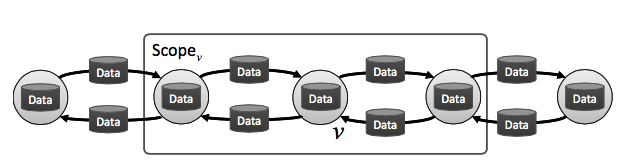
圖片 2. Data Graph (資料來源: [3])
Data graph 模式將參數之間的計算依賴關係建構成 data graph: 節點是參數,邊則是節點跟節點之間的計算依賴關係。
以 Pagerank 為例。在 data graph當中,每一個節點儲存對應的原圖節點的 Pagerank值,如果原圖兩節點中有連結,則在 data graph 裡兩個節點也會有連結。 data graph 當中的節點,僅可以操作到鄰居節點以及連結邊上的數值。一個節點的工作則是: 將自身的 Pagerank 值,散布給所有的鄰居。
Pregel [4] 是由 Google 提出的 data graph 計算框架。 Pregel 會以連續的超階段 (supersteps) 的方式執行使用者程式。在第 S 個超階段,框架會平行地執行使用者所提供的節點函式,節點可以收到第 S - 1 超階段傳遞給他的值,加以計算,在傳遞給鄰居節點,其鄰居節點會在 S + 1 超階段接收到值。等到所有節點都完成計算,才能一起進入到 S + 1 超階段。Pregel 很適合處理圖形演算法,像是 Pagerank, 最短路徑, 或者圖形分群。雖然 Google 並沒有將 Pregel 開源化,但目前在開源社群以有對應的開源版本,其名稱是 Apache Giraph。
GraphLab [3] 是由 CMU 實驗室團隊所提出的分布式 data graph 計算框架。不同於 Pregel,GraphLab 並不強制使用者的程序必須要等到所有的節點都結束計算,才能到下一個超階段。而是,它允許節點能夠異步地 (asynchronously) 執行程式。此外,GraphLab 提供三種不同強度的一致性模型 (consistency model):vertex consistency, edge consistency, 和 full consistency。用以確保當一個節點在執行程式的時候,不會有另外一個程序也在更改同樣的鄰居節點,而產生的一致性問題。
PowerGraph [5] 則是 GraphLab 強化版本,設計處理圖形中普遍存在的超高 Degree 節點會產生的問題。此外,有另一個版本 GraphChi [6] ,則是致力於只用一台機器,實作出 GraphLab 的計算邏輯。
Parameter Server 模式
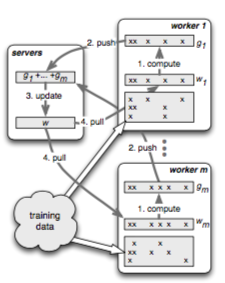
圖形 3. Parameter Server (資料來源: [7])
Parameter Server [7] 由 server 集群和 worker 集群所組成。訓練資料集合是散步在 worker 當中, worker 根據自己所擁有的訓練資料計算模型參數。而 Server 維護分步式的 Hashtable,使得 worker 可以從中擷取正在計算中的模型參數,以及設置其計算的結果。
以 logistic regression 為例子,一個計算的循環如下: worker 先從 server 取得目前最新的模型參數。接著,worker 根據本地的資料開始計算 gradient descent value ,算完之後,再把 gradient descent 的值回傳給 server 做加總。
Petuum [8] 也是一套基於 Parameter Server 設計的計算框架。作者們提出 Stale Synchronous Parallel (SSP) 的通訊概念,以減少為了同步問題,worker 的等待時間。使用者可以設置 Stale 的值 S。當一個跑得比較快的 worker 已經算好一個模型參數值,他可以不用等其他也會算到相同參數的 worker,繼續在本地更新模型的參數,直到比較快的 worker 跟比較慢的 worker 所計算的模型參數版本差了 S 個版本,比較快的 worker 才需要停下來等待。
Reference
[1] Mahout. http://mahout.apache.org. (n.d.). Mahout. http://mahout.apache.org. Retrieved February 22, 2015, from http://mahout.apache.org/
[2] Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauly, M., et al. (2012). Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Nsdi, 15–28.
[3] Low, Y., Gonzalez, J. E., Kyrola, A., Bickson, D., Guestrin, C., & Hellerstein, J. M. (2014). GraphLab: A New Framework For Parallel Machine Learning. CoRR Abs/1204.6078, cs.LG.
[4] Malewicz, G., Austern, M. H., Bik, A. J. C., Dehnert, J. C., Horn, I., Leiser, N., & Czajkowski, G. (2010). Pregel: a system for large-scale graph processing. Sigmod, 135–146. http://doi.org/10.1145/1807167.1807184
[5] Gonzalez, J. E., Low, Y., Gu, H., Bickson, D., & Guestrin, C. (2012). PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs. Osdi, 17–30.
[6] Kyrola, A., Blelloch, G. E., & Guestrin, C. (2012). GraphChi: Large-Scale Graph Computation on Just a PC. Osdi, 31–46.
[7] Li, M., Andersen, D. G., Smola, A. J., & Yu, K. (2014). Communication Efficient Distributed Machine Learning with the Parameter Server. Nips, 19–27.
[8] Dai, W., Wei, J., Zheng, X., Kim, J. K., Lee, S., Yin, J., et al. (2013). Petuum: A Framework for Iterative-Convergent Distributed ML. CoRR Abs/1204.6078, stat.ML.
[9] Dean, J., & Ghemawat, S. (2008). MapReduce: simplified data processing on large clusters. Communications of the ACM, 51(1). http://doi.org/10.1145/1327452.1327492
[10] Hadoop. http://hadoop.apache.org. (n.d.). Hadoop. http://hadoop.apache.org. Retrieved February 22, 2015, from http://hadoop.apache.org/
[11] Giraph. http://giraph.apache.org. (n.d.). Giraph. http://giraph.apache.org. Retrieved February 22, 2015, from http://giraph.apache.org/
Go Top