Summary
Big machine learning is hard because (1) the amount of traning data is huge (2) the number of parameters is large. This note summarizes three paradigms of distributed architecture for large-scale machine learning problem: MapReduce, Data Graph, and Parameter Server.
Why should we build distributed system for large-scale machine Learning?
Large-scale has two meanings: (1) the amount of training data is huge which can not easily fit in a machine. (2) the number of parameters is too large to be stored and manipulated by a single machine. Therefore, the large-scale machine learning and data mining usually cannot be solved by a single machine. In stead, developers need to construct their machine learning algorithms into a distributed system.
MapReduce Approach
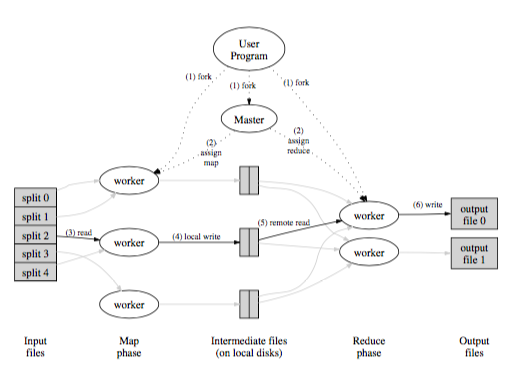
Figure 1. MapReduce (source: [9])
MapReduce [9] is a well-known distributed computing model on clusters, and Apache Hadoop [10] is the best known open source counterpart for MapReduce. In general, MapReduce contains two phases: map phase and reduce phase. In map phase, the provided map program should process the input chunks into key-value pairs. After map phase, the key-value pairs will be shuffled into the specific reduce nodes according to the hash value of the key. The reducers will receive the list of values with the corresponding key, perform its reduce function, and store the output into a distributed file system.
Many research tried to fit the existing machine learning algorithms into MapReduce framework. They need to transform original algorithms into map functions and reduce functions in multiple iterations. Mahout [1] is a well-known open source for large-scale machine learning mainly based on Hadoop.
Hadoop is designed to store the output of one map-reduce phase into disk; however, many machine learning algorithms need iterative calculation until the termination condition is achieved (e.g. the algorithms in gradient decent fashion). Multiple iteration computing on Hadoop can cause huge amount of I/O time and deteriorate the performance.
To tackle with this problem, Spark [2] provides Resilient Distributed Datasets (RDD) for in-memory computation, which can cache the output of one MapReduce iteration into memory and load it from memory in the next iteration, so RDD can improve performance by avoiding disk I/O. According to their experiments, Spark can have 20x speedup over Hadoop in logistic regression and k-means algorithm. MLlib is a popular machine learning framework based on Spark.
Another problem for MapReduce approach mentioned by Low et al. (2012) [3] is that the framework may generate huge amount of duplicated messages in the map phase and increase network cost. Taking Pagerank as an example, the high degree nodes need to send multiple duplication of its Pagerank value to its neighbors in map phase. The network traffic may reduce the performance of the algorithms.
Data Graph Approach
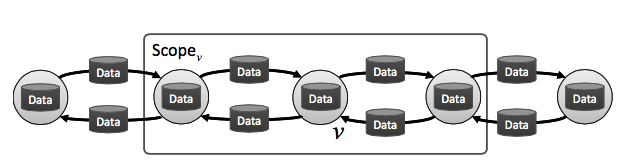
Figure 2. Data Graph (source: [3])
The data graph approach means to model the computation relationship between the variables in the machine learning algorithm into a data graph: the nodes are the variables and the edges are the connection of message passing.
Take Pagerank for example (which is usually the "Hello World" program for Data Graph approach). Each node in data graph represents stores the Pagerank value for a vertex in original graph. The links in data graph represent the connections between vertices. A node in a data graph can access the values on it's neighbor nodes and adjcent links. The Pagerank job of a node in the data graph is to distribute its Pagerank value to the neigbor nodes.
Pregel [4] is a distributed graph computing framework. The programs in Pregel are executed in continuous supersteps. In each superstep S, the framework call the defined functions on the vertices in parallel, and the vertex can read the message sent to it in S-1, and also send messages to other vertices which can read the message in S+1 superstep. Pregel is well suited in graph algorithms like Pagerank, shortest path, and clustering. Although Google does not release the source code of Pregel to public, but it has an open source counterpart called Apache Giraph [11].
GraphLab [3] is an another distributed graph computing framework. Unlike Pregel, GraphLab does not have synchronous supersteps for message passing. Instead, it uses vertex functions in asynchronous fashion to specify what kind of computation is performed and which vertices will run in the next round, and it uses three different consistency models (vertex consistency, edge consistency, and full consistency) to assure serializablility. GraphLab is improved in the next version PowerGraph [5], which can deal with high degree vertices by splitting them into multiple vertices. Besides, GraphLab has an variant called GraphChi [6], which focuses on how to implement graph computation logic in a single machine.
Parameter Server Approach
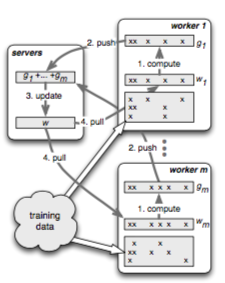
Figure 3. Parameter Server (source: [7])
Parameter Server [7] is a servers-workers style distributed computing framework. The servers storing global variables in distributed hashtable fashion, supporting pull, push, and aggregation operations of global variables for the workers. The training data is partitioned in the workers where the main computation happens.
Taking distributed logistic regression as an example, one calculation cycle is as follows: the workers pull the global weights from the servers. Each worker computes its local gradient descent value according its data, and then push back to the servers for aggregation. After the aggregation, the workers pull the global weights again.
Petuum [8] also follows Parameter Server architecture. They developed a more specific communication mechanism called Stale Synchronous Parallel(SSP) to mitigate the workers from waiting. Users can set the parameter staleness S. A fastest worker need to wait if it is faster than the slowest worker S iterations. SSP can reduce the network traffic because workers do not need to spend too much time waiting for other worker updates.
Reference
[1] Mahout. http://mahout.apache.org. (n.d.). Mahout. http://mahout.apache.org. Retrieved February 22, 2015, from http://mahout.apache.org/
[2] Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauly, M., et al. (2012). Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Nsdi, 15–28.
[3] Low, Y., Gonzalez, J. E., Kyrola, A., Bickson, D., Guestrin, C., & Hellerstein, J. M. (2014). GraphLab: A New Framework For Parallel Machine Learning. CoRR Abs/1204.6078, cs.LG.
[4] Malewicz, G., Austern, M. H., Bik, A. J. C., Dehnert, J. C., Horn, I., Leiser, N., & Czajkowski, G. (2010). Pregel: a system for large-scale graph processing. Sigmod, 135–146. http://doi.org/10.1145/1807167.1807184
[5] Gonzalez, J. E., Low, Y., Gu, H., Bickson, D., & Guestrin, C. (2012). PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs. Osdi, 17–30.
[6] Kyrola, A., Blelloch, G. E., & Guestrin, C. (2012). GraphChi: Large-Scale Graph Computation on Just a PC. Osdi, 31–46.
[7] Li, M., Andersen, D. G., Smola, A. J., & Yu, K. (2014). Communication Efficient Distributed Machine Learning with the Parameter Server. Nips, 19–27.
[8] Dai, W., Wei, J., Zheng, X., Kim, J. K., Lee, S., Yin, J., et al. (2013). Petuum: A Framework for Iterative-Convergent Distributed ML. CoRR Abs/1204.6078, stat.ML.
[9] Dean, J., & Ghemawat, S. (2008). MapReduce: simplified data processing on large clusters. Communications of the ACM, 51(1). http://doi.org/10.1145/1327452.1327492
[10] Hadoop. http://hadoop.apache.org. (n.d.). Hadoop. http://hadoop.apache.org. Retrieved February 22, 2015, from http://hadoop.apache.org/
[11] Giraph. http://giraph.apache.org. (n.d.). Giraph. http://giraph.apache.org. Retrieved February 22, 2015, from http://giraph.apache.org/
Go Top