"Learning to rank: from pairwise approach to listwise approach," Cao, ICML, 2007.
Authors: Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, Hang Li The following figures are all copied from this paper.
Algorithm
Unlike pairwise rank-learning method like RankSVM, this work proposed a listwise rank learning framework where training instances are rank lists instead of document pairs. To predict a rank list for a query $latex q_i $, this work models the score of the rank permutation as a probability function as follows, in which $latex s_{\pi(j)} $ is a scoring function for a document in j position and \phi is a positive strict increasing function often using exponential function.
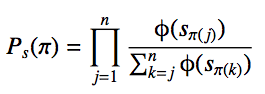
The objective function of learning is to minimize the loss of list between training data and predicting data.
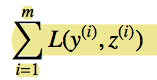
To reduce computation complexity, it use top K probability modeling the likelihood of top K documents order. In this research, k is selected as 1, and the scoring function is trained by Neural network optimized by gradient descent.
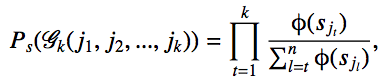
And the loss function will be defined as the cross entropy between training data and predicting list.
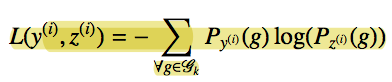
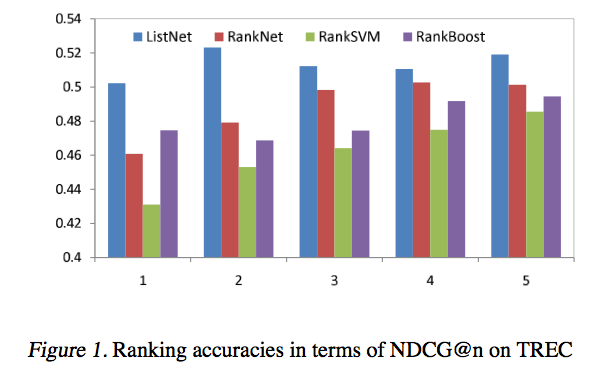
Experiments Result
Comparing with pairwise methods: RankBoost, RankSVM and RankNet, ListNet have better results in both MAP and NDCP measurements.

My Opinion
It is charming that ListNet directly model the retrieval directly based on ranking list, which is still the search engine paradigm today. However, I am curious about why the probability of permutations performs well and results with different parameters "K": beyond the consideration of computation complexity, will it work more precisely with a larget "K"?
Go Top