"Nonlinear dimensionality reduction by locally linear embedding," Roweis & Saul, Science, 2000.
The following figures are all copied from the essay.
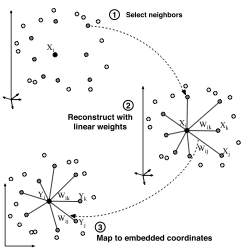
The main purpose of this method is to reduce the data from high dimensions to low dimensions while maintaining instances local relative distances at the same time. There are three main steps: (1) selecting k neighbors (2) calculate contribution weights $latex W_{ij} $ (3) reducing dimensions. The algorithm can be used for not only text corpus, but also images.
First, select the k nearest neighbors for each instance, where "k" is a parameter, and distances between between neighbors will be maintain.
Second, calculate the weights $latex W_{ij} $, the contribution of $latex j$ to $latex i$ , between the selected instance $latex i $ and its neighbors $latex j $ by minimizing the following cost function with two constraints: (1) $latex X_j $ are the neighbors of $latex X_i $. (2)
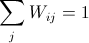
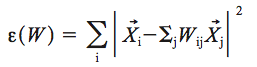
Third, with the following cost function fixing $latex W_{ij}$ , transform instances from high-dimension X to low-dimension Y, which can be seen as a eigenvalue problem.
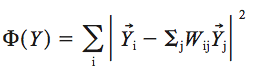
Advantages
(1) Invariant Due to the cost function is a sum function, for image processing, it will be not sensitive to geometric transformation. (2) Small amount of parameters The method use small amount of parameters, only k for selecting neighbors. ##
Disadvantages
If selecting neighbors with brute force comparison, it will consume much of time when data size raising. May be it can be solved by locality sensitive hash method to find nearest neighbors efficiently.
Go Top