PLSI & LDA
Origin source: "Probabilistic latent semantic indexing," T. Hofmann, SIGIR, 1999. "Latent Dirichlet allocation," D. Blei, A. Ng, and M. Jordan. . Journal of Machine Learning Research, 3:993–1022, January 2003 The following figures and formula are copied from above papers.
PLSI and LDA are both hidden-class decomposition method ( or dimension reduction method ) but are different in modeling approaches; through mapping documents from high-dimension to low-dimension hidden class space, the ambiguous words relationship can be detected such that improve information retrieval precision.
PLSI
PLSI use the hidden-class decomposition technique PLSA, which is a generative probability model assuming a word in a specific document is generated as follows: (1) randomly pick a hidden-topic z for the document following P(z|d) (2) randomly pick a word w conditioning the topic z following P(w|z) (3) sum up all hidden topic result of generating word w. In other words, wordis relative to unobservable hidden-topic whose probability can not be calculated directly except an EM method, which compose with two steps: expectation step and maximization step.
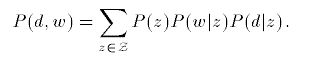
In E step, calculate posterior probabilities given document and word as following formula.
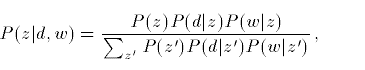
In M step, calculate prior probabilities.
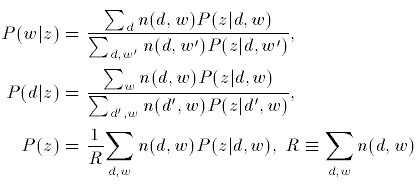
Besides, to avoid overfitting, the authors proposed TEM method, which adds a power coefficient $latex \beta $ to original EM formula as follows:
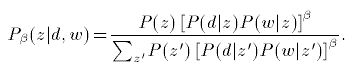
LDA
LDA is a graphical model approach to model words generation process.
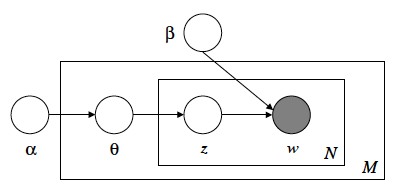
Advantages
For PLSI, the formula in the M-step minimize word perplexity directly. For LDA, because LDA is a graphical model, LDA can be extended to more complex model.
Go Top